








MCP服务实战—操作mysql数据库
1.简介
MCP 是一个开放协议,于 2024 年 11 月由 Anthropic 推出,旨在标准化应用程序如何向大型语言模型(LLM)提供上下文,为 AI 模型连接各种数据源和工具提供了标准化接口,就像 USB-C 为设备连接各种外设和配件提供标准化方式一样 。
2.协议架构
MCP采用典型的CS架构(客户端-服务器),主机应用可以连接多个服务器:
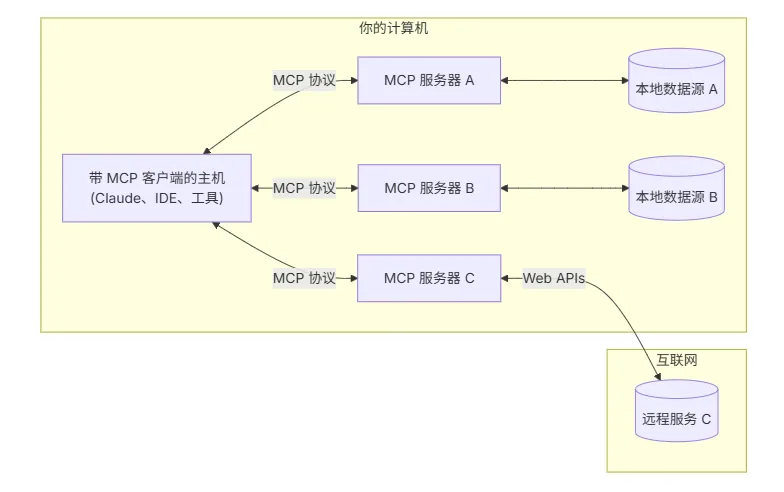
● MCP Hosts: 如 Claude Desktop、IDE 或 AI 工具,希望通过 MCP 访问数据的程序
● MCP Clients: 维护与服务器一对一连接的协议客户端
● MCP Servers: 轻量级程序,通过标准的 Model Context Protocol 提供特定能力
● 本地数据源: MCP 服务器可安全访问的计算机文件、数据库和服务
● 远程服务: MCP 服务器可连接的互联网上的外部系统(如通过 APIs)
核心功能
工具提供 :MCP 服务器可以提供工具,这些工具是可被 LLM 调用的函数,但需要用户批准,使 LLM 能够执行特定的操作或任务,从而扩展了模型的功能。
资源访问 :允许 LLM 访问各种数据源,包括本地数据源,如计算机上的文件、数据库和服务,以及远程服务,如通过 APIs 访问的互联网上的外部系统,为模型提供了更丰富的信息输入。
上下文管理 :MCP 能够对齐模型观察到的内容、记忆的内容以及采取行动的能力,通过标准化的接口和协议,确保模型在与外部工具和数据源交互时,能够正确地处理和管理上下文信息。
3.MCP实战准备
3.1 前期准备
python和conda环境
ollama版本和Qwen3-8B模型准备
搭建MySQL数据库
python和conda环境参考博文:
Cherry Studio参考博文:本地部署Deepseek R1模型,搭建个人知识库
3.2 部署本地模型
下载ollama,下载Qwen3模型相关操作参考博文:本地部署Deepseek R1模型,搭建个人知识库
点击模型查看deepseek R1模型相关下载说明,根据自身硬件选择合适的阉割版,这里选择Qwen3-8B:
3.3 搭建MYSQL数据库
1.通过docker来部署mysql服务
[root@tzy ~]# docker pull mysql:latest //拉取MySQL最新镜像文件。
[root@tzy ~]# mkdir -p /mysql/conf //创建文件夹
[root@tzy conf]# cat my.cnf //创建my.cnf
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
[root@tzy conf]# docker run -dit -p 3306:3306 -v /mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=yourpassword --name tzy-mysql mysql //运行容器
[root@tzy conf]# docker exec -it tzy-mysql /bin/bash //进入容器
bash-5.1# mysql -u root -p //进入MySQL控制窗口my.cnf文件模板
[client]
port = 3306
[mysqld]
# Mysql服务的唯一编号 每个mysql服务Id需唯一
server-id = 1
# 服务端口号 默认3306
port = 3306
# mysql安装根目录
basedir = /usr/local/mysql
# mysql数据文件所在位置
datadir = /usr/local/mysql/data
secure-file-priv= /var/lib/mysql
# 允许访问的IP网段
bind-address = 0.0.0.0
# 只能用IP地址检查客户端的登录,不用主机名
skip_name_resolve = 1
# 数据库默认字符集,主流字符集支持一些特殊表情符号(特殊表情符占用4个字节)
character-set-server = utf8mb4
# 数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server = utf8mb4_general_ci
# 设置client连接mysql时的字符集,防止乱码
init_connect='SET NAMES utf8mb4'
# 是否对sql语句大小写敏感,1表示不敏感
lower_case_table_names = 1
# 最大连接数
max_connections = 400
# 最大错误连接数
max_connect_errors = 1000
# TIMESTAMP如果没有显示声明NOT NULL,允许NULL值
explicit_defaults_for_timestamp = true
# SQL数据包发送的大小,如果有BLOB对象建议修改成1G
max_allowed_packet = 128M
# MySQL连接闲置超过一定时间后(单位:秒)将会被强行关闭
# MySQL默认的wait_timeout 值为8个小时, interactive_timeout参数需要同时配置才能生效
interactive_timeout = 1800
wait_timeout = 1800
# 内部内存临时表的最大值 ,设置成128M。
# 比如大数据量的group by ,order by时可能用到临时表,
# 超过了这个值将写入磁盘,系统IO压力增大
tmp_table_size = 134217728
max_heap_table_size = 134217728
# 慢查询sql日志设置
slow_query_log = 1
slow_query_log_file = slow.log
# 检查未使用到索引的sql
log_queries_not_using_indexes = 1
# 针对log_queries_not_using_indexes开启后,记录慢sql的频次、每分钟记录的条数
log_throttle_queries_not_using_indexes = 5
# 慢查询执行的秒数,必须达到此值可被记录
long_query_time = 8
# 检索的行数必须达到此值才可被记为慢查询
min_examined_row_limit = 100
# mysql binlog日志文件保存的过期时间,过期后自动删除
binlog_expire_logs_seconds = 6048004.搭建mysql-mcp服务器
4.1 环境准备
打开powershell,新建目录sql_mcp_server_pro,新建两个文件.env,server.py。然后conda来激活和创建虚拟环境,在通过python pip包管理工具来安装依赖包:
# 1.新建文件夹和文件
mkdir sql_mcp_server_pro
touch .env pkg.txt
# 2.开启虚拟环境
conda create -n mcp_env python=3.12.4
conda activate mcp_env
# 3.安装相关依赖包
pip install -r pkg.txt
# pkg文件内容
mcp
mysql-connector-python
uvicorn
python-dotenv
starletteenv文件内容写入MySQL数据库连接信息,如下:
MYSQL_HOST=localhost
MYSQL_PORT=3306
MYSQL_USER=root
MYSQL_PASSWORD=****
MYSQL_DATABASE=testserver.py代码展示:
import os
import uvicorn
from mcp.server.sse import SseServerTransport
from mysql.connector import connect, Error
from mcp.server import Server
from mcp.types import Tool, TextContent
from starlette.applications import Starlette
from starlette.routing import Route, Mount
from dotenv import load_dotenv
def get_db_config():
"""从环境变量获取数据库配置信息
返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称
异常:
ValueError: 当必需的配置信息缺失时抛出
"""
# 加载.env文件
load_dotenv()
config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all([config["user"], config["password"], config["database"]]):
raise ValueError("缺少必需的数据库配置")
return config
def execute_sql(query: str) -> list[TextContent]:
"""执行SQL查询语句
参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔
异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = []
for statement in statements:
try:
cursor.execute(statement)
# 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
# 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row))
# 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
)
# 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}")
except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续
return [TextContent(type="text", text="\n---\n".join(results))]
except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [TextContent(type="text", text=f"执行查询时出错: {str(e)}")]
def get_table_name(text: str) -> list[TextContent]:
"""根据表的中文注释搜索数据库中的表名
参数:
text (str): 要搜索的表中文注释关键词
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql)
def get_table_desc(text: str) -> list[TextContent]:
"""获取指定表的字段结构信息
参数:
text (str): 要查询的表名,多个表名以逗号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql)
def get_lock_tables() -> list[TextContent]:
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;"""
return execute_sql(sql)
# 初始化服务器
app = Server("operateMysql")
@app.list_tools()
async def list_tools() -> list[Tool]:
"""列出可用的MySQL工具
返回:
list[Tool]: 工具列表,当前仅包含execute_sql工具
"""
return [
Tool(
name="execute_sql",
description="在MySQL8.0数据库上执行SQL",
inputSchema={
"type": "object",
"properties": {
"query": {"type": "string", "description": "要执行的SQL语句"}
},
"required": ["query"],
},
),
Tool(
name="get_table_name",
description="根据表中文名搜索数据库中对应的表名",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表中文名"}
},
"required": ["text"],
},
),
Tool(
name="get_table_desc",
description="根据表名搜索数据库中对应的表结构,支持多表查询",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表名"}
},
"required": ["text"],
},
),
Tool(
name="get_lock_tables",
description="获取当前mysql服务器InnoDB 的行级锁",
inputSchema={"type": "object", "properties": {}},
),
]
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "execute_sql":
query = arguments.get("query")
if not query:
raise ValueError("缺少查询语句")
return execute_sql(query)
elif name == "get_table_name":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_name(text)
elif name == "get_table_desc":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_desc(text)
elif name == "get_lock_tables":
return get_lock_tables()
raise ValueError(f"未知的工具: {name}")
sse = SseServerTransport("/messages/")
# Handler for SSE connections
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request._send
) as streams:
await app.run(streams[0], streams[1], app.create_initialization_options())
# Create Starlette app with routes
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
if __name__ == "__main__":
uvicorn.run(starlette_app, host="0.0.0.0", port=9000)4.2 启动MCP服务
进入创建的目录,然后运行python server.py命令:
cd .\sql_mcp_server_pro\
python server.py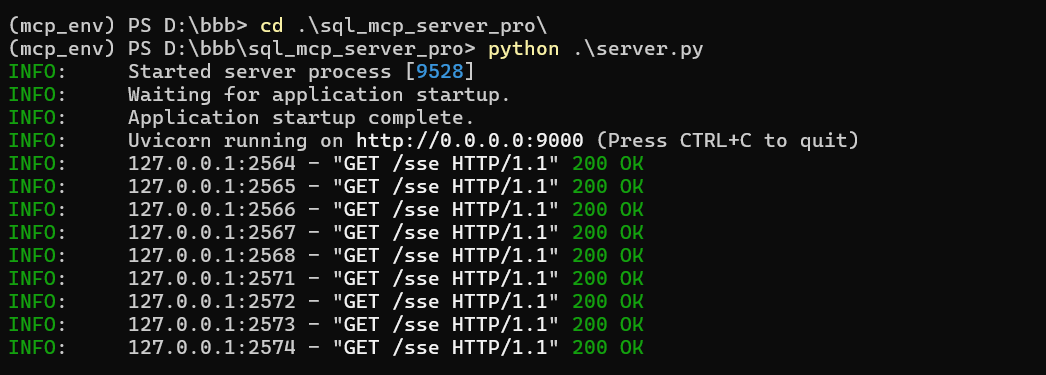
可以看到MCP服务启动成功了。
4.3 配置客户端
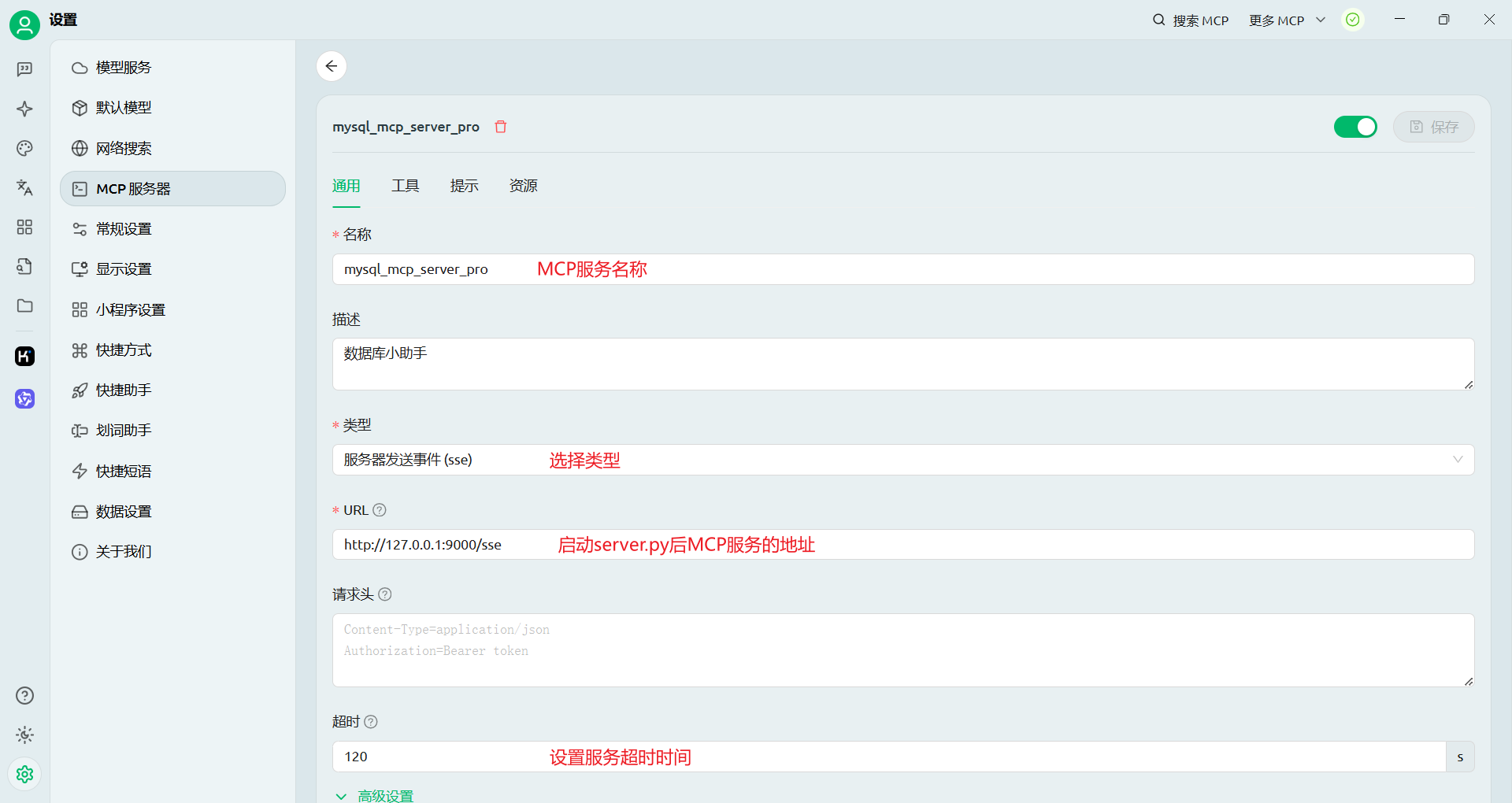
打开Cherry Studio软件,点击设置MCP服务器,添加MCP服务器快速创建:
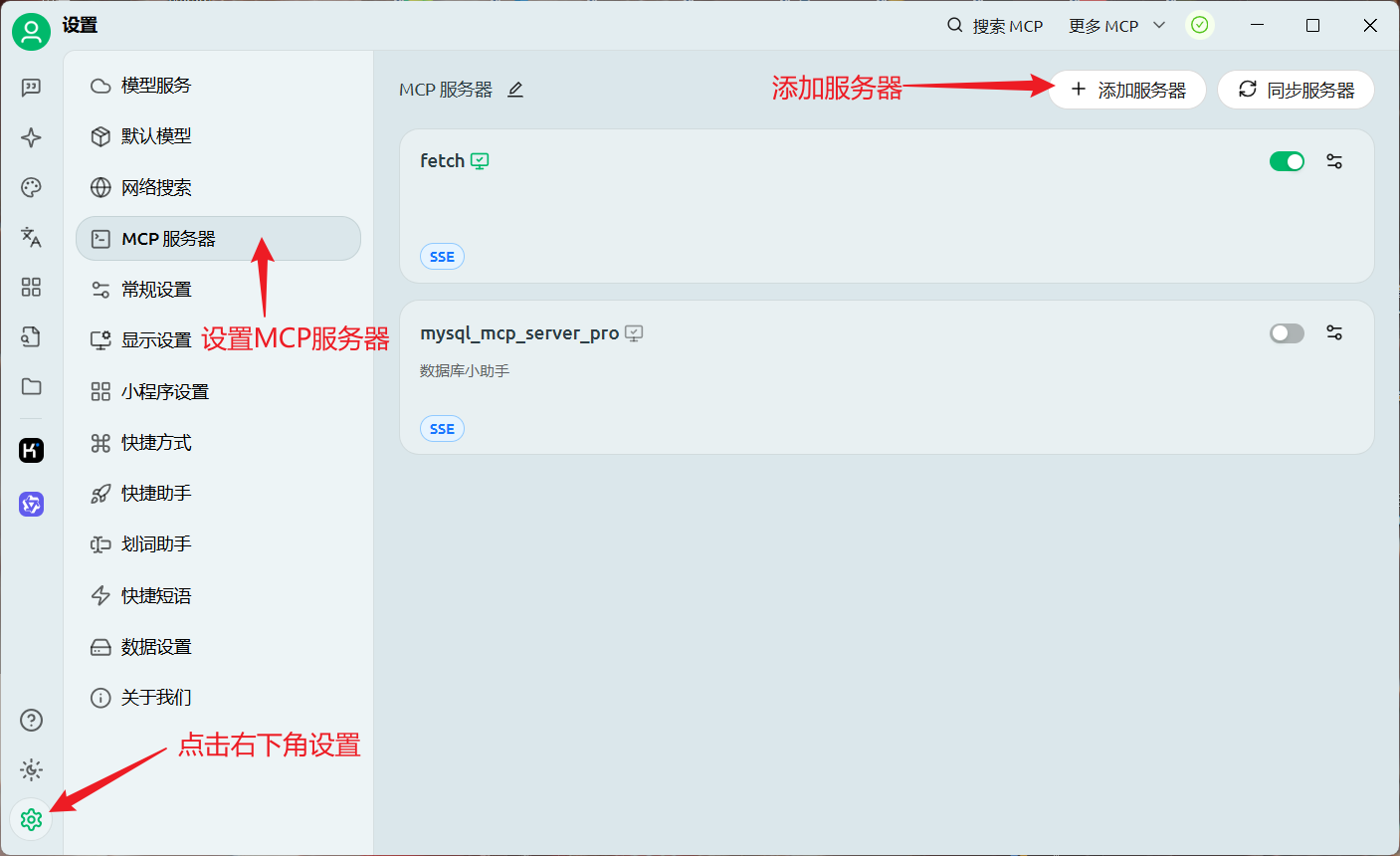
配置MCP服务器,如图:
5.function测试
新建助手,在对话框中选择刚刚创建的MCP服务器:
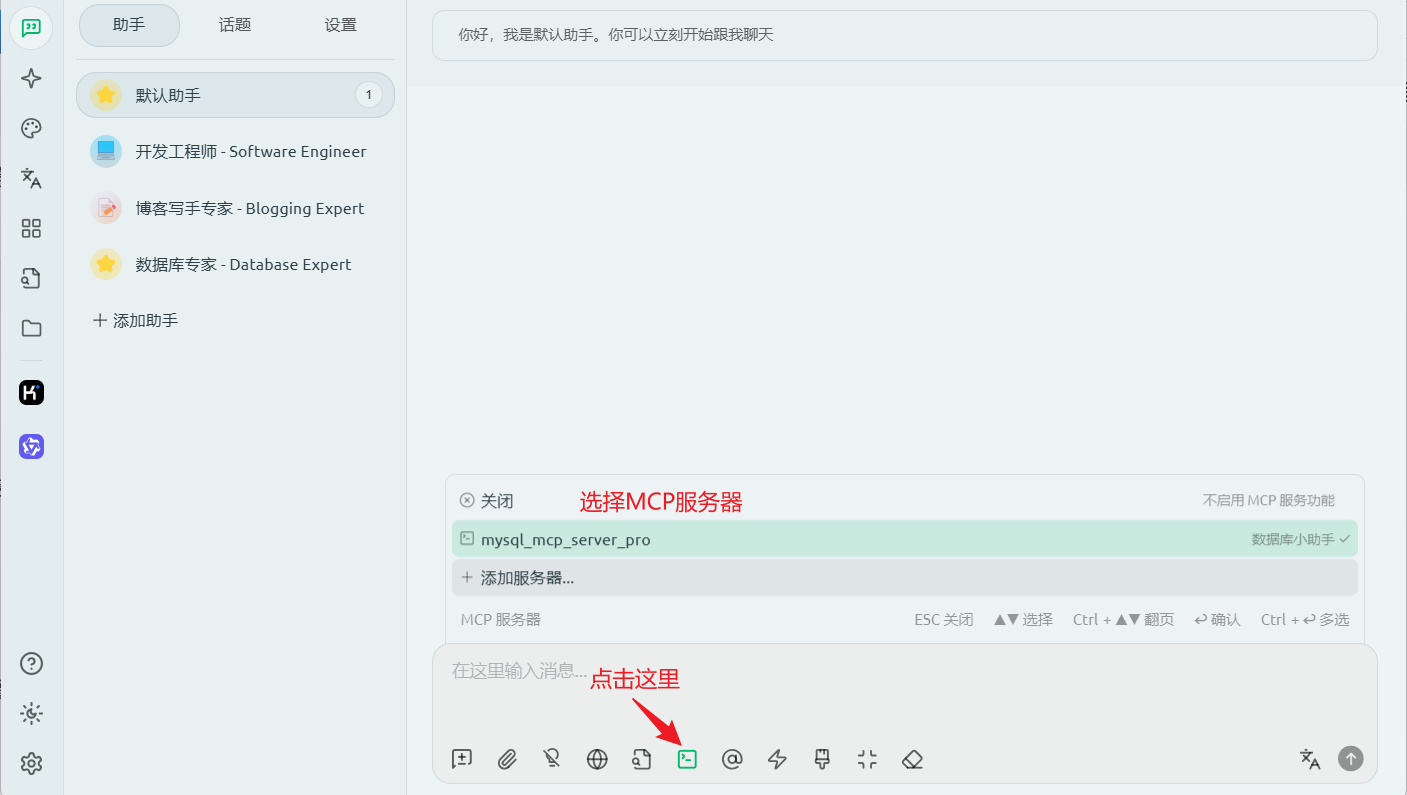
接下来开始测试MCP服务,来进行数据表的增删改查操作。
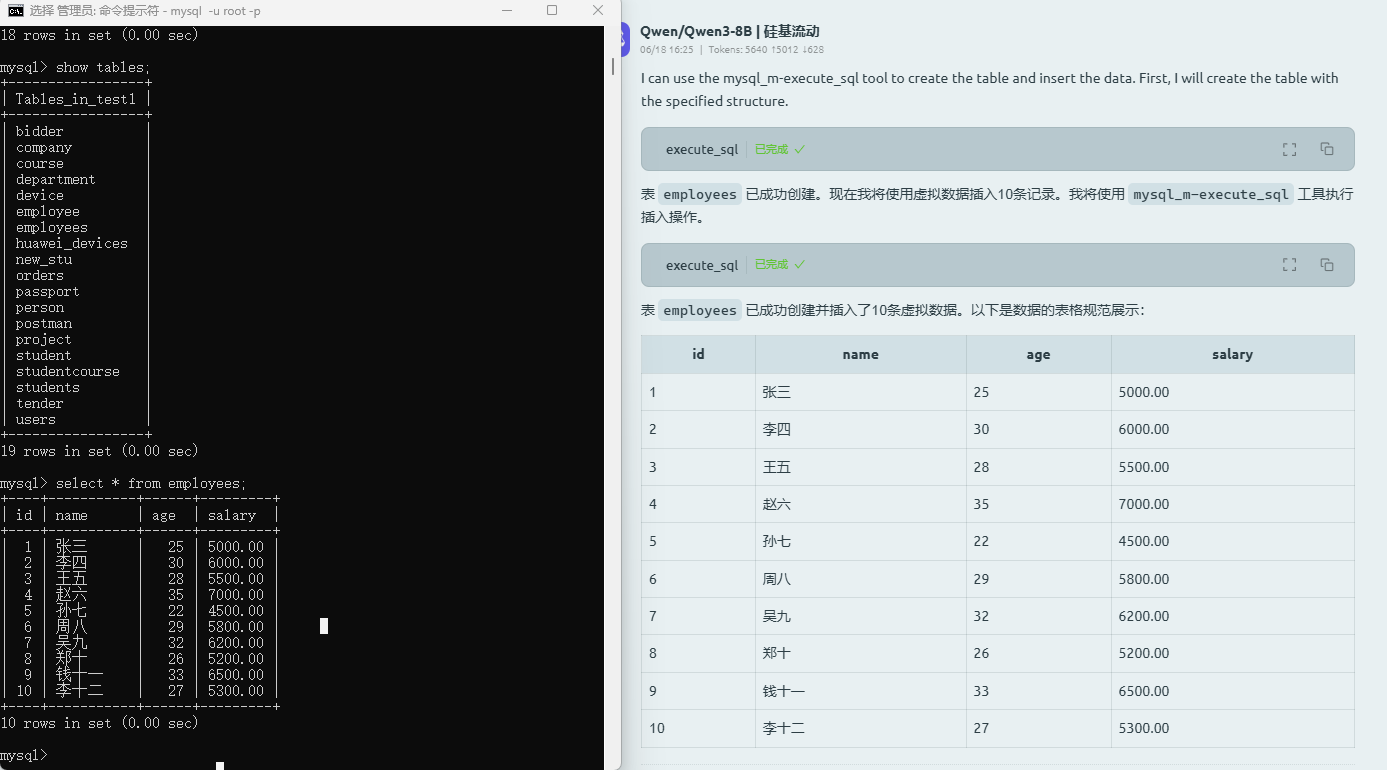
输入提示词:
创建一张员工表表名使用英文名,并插入10条虚拟数据包括姓名年龄工资,使用表格规范的展示出来数据。
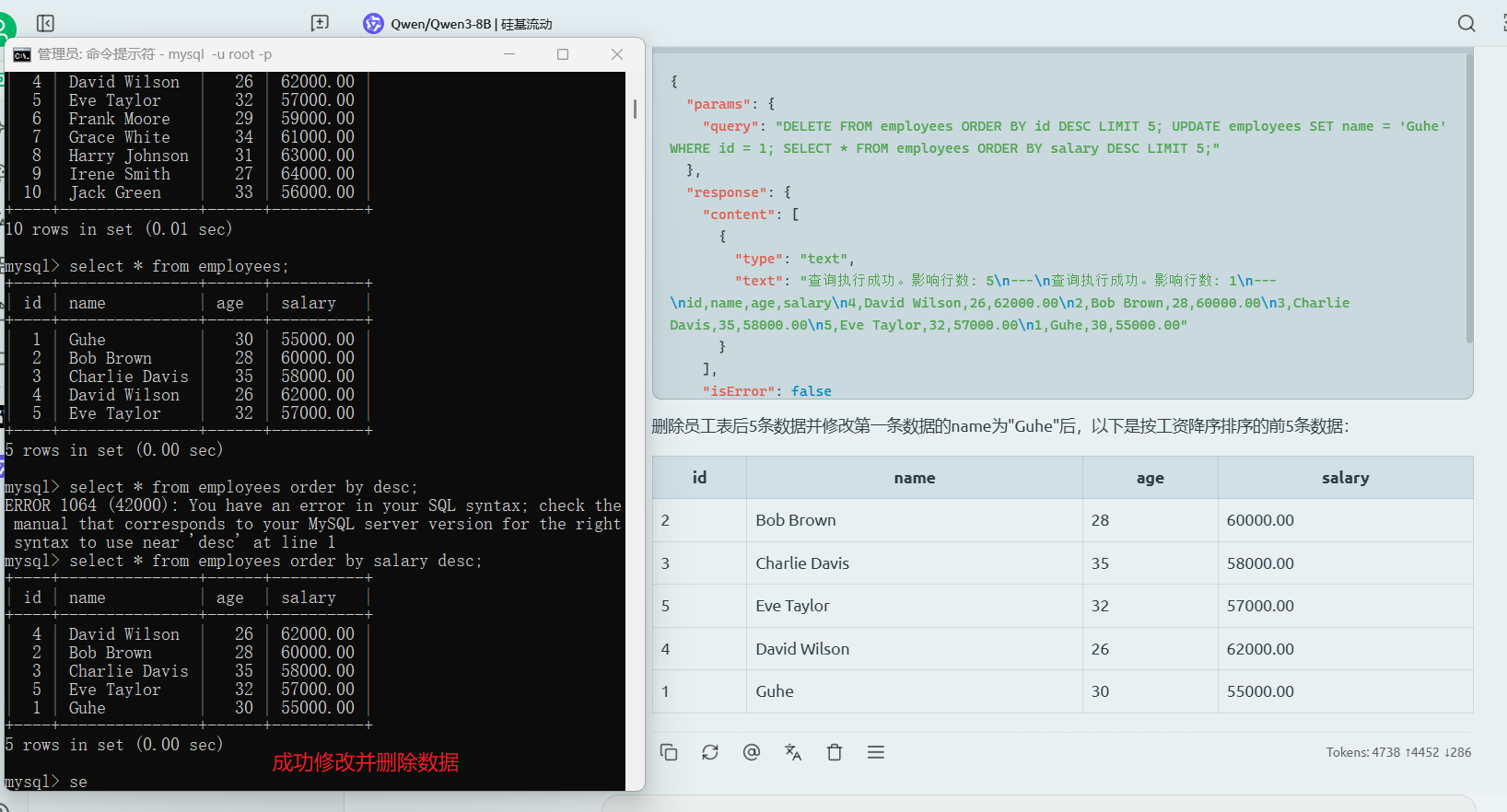
删除员工表后5条数据,并将第一条数据的name修改为Guhe,然后使用降序排序工资展示前5条数据。
参考链接
希望这篇博客对你有帮助!如果有其他问题,欢迎随时提问!







